How Should I Accept Patches?
I believe strongly in the Bazaar model of software development. I want to use the Bazaar model on the projects that I’m developing, but I’m running into a problem. To adopt the Bazaar model, I have to decide on how I’m going to allow people to submit patches. There’s a ton of different ways to do this. In order to narrow things down, I’ve come up with three different qualities that I want my patch submission process to have. As it turns out, it’s hard to find one that has those three qualities.
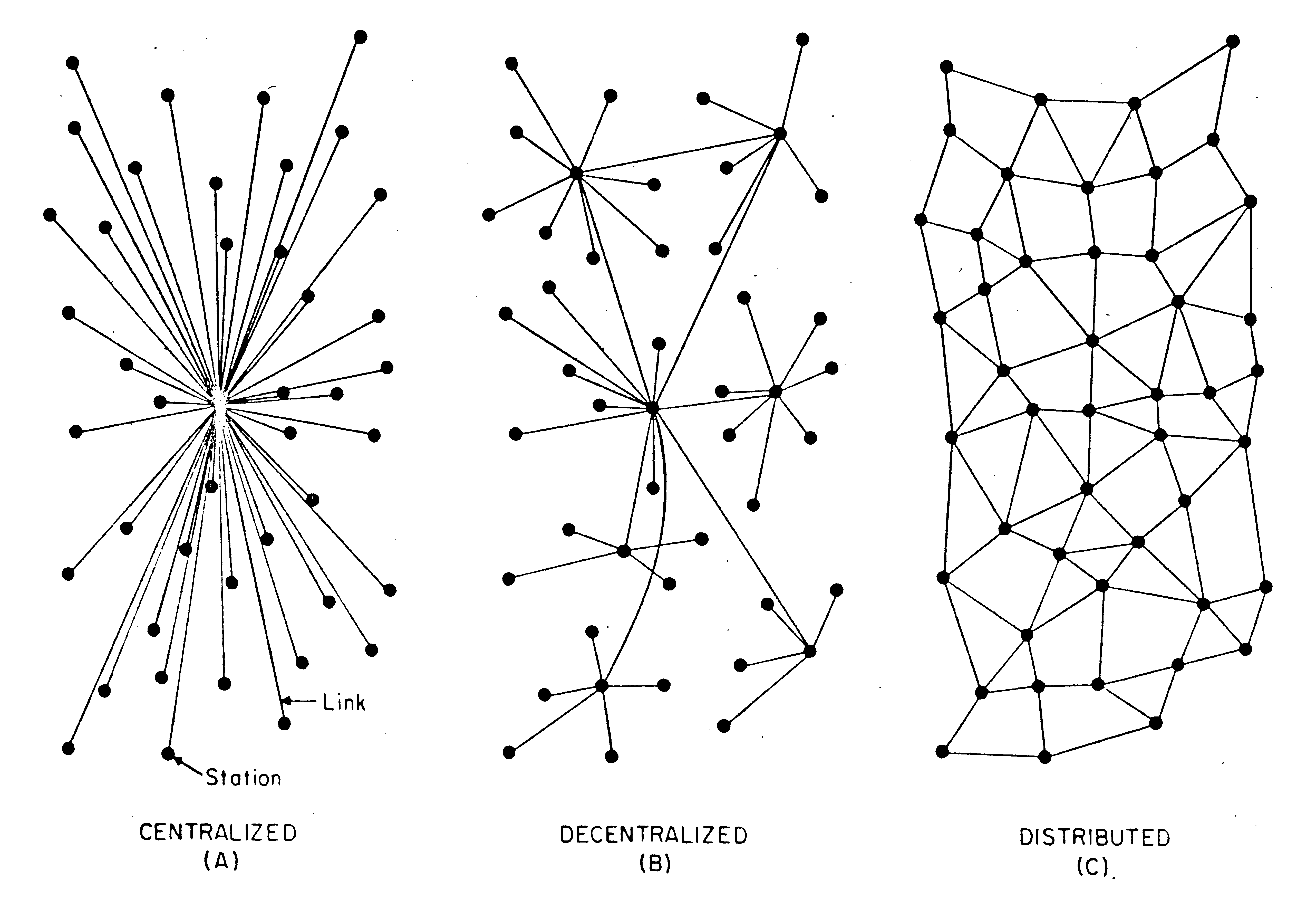
One thing that I should mention up front is that I only use Git. I don’t have very much experience with other version control systems, and I’m not willing switch at the moment. If I ever decide to switch, then I’ll have to revisit this question again. I do use proprietary software myself, but I’ve been slowly weening off it overtime. There’s plenty of free software software-development tools out there. If there weren’t so many, then I would be more open to using proprietary ones. Issues with dev tools can be frustrating, but they’re much more frustrating when the tools are proprietary because there’s nothing that I can do to fix them. Plus, there’s plenty of people who would be less likely to contribute if proprietary software was required. Over the years, I’ve created a lot of public repos across three different project hosts (GitHub, GitLab and Pagure), but I’ve never received a single contribution. This is to be expected. According to a 2013 analysis by Donnie Berkholz, In his 1964 memorandum, On Distributed Communications: I. Introduction to Distributed Communications Networks, Paul Baran wrote: Although one can draw a wide variety of networks, they all factor into two components: centralized (or star) and distributed (or grid or mesh) (see Fig. 1). Baran assigned letters to each of those network types, but I actually think that it makes more sense to assign them numbers: 0 for centralized, 1 for decentralized and 2 for distributed. Few networks are a perfect 0, 1 or 2. Take DNS for example. Anyone can run their own DNS recursor, but you have to get permission from one of the twelve DNS root operators to run a DNS root node. This puts DNS somewhere between a centralized and decentralized network. I give it a score of 0.8 (mostly decentralized). Email, as another example, is maybe a 1.2. While you need the decentralized infrastructure of mail servers to send and receive email, you can still read and compose mail offline using the distributed infrastructure of your own personal computers. Ideally, my patch system would be a perfect 2. Being completely distributed would have a few advantages: GitHub is proprietary, and, I can’t think of a single advantage that GitHub has over its free software alternatives. There’s plenty of things that GitHub does well. I like GitHub issues and pull requests, but I don’t see how they’re any better than their GitLab or Pagure equivalents. The only potential advantage would be the fact that so many people already use GitHub. That being said, I’m skeptical that this would actually be an advantage for patches specifically. I could see someone not reporting a bug because they don’t already have an account for something or because they don’t want to learn how to use a new system. If someone’s already willing to write a patch, they’re probably willing to spend a few minutes registering a new account and learning a new system. I want to emphasize that they’re probably willing to spend a few minutes getting set up. If the setup process becomes a whole ordeal, then there’s a good chance that they’ll give up on submitting the patch. There’s two different editions of GitLab, the Enterprise Edition and the Community Edition. The Community Edition is available under the MIT license (which is a free software license). The Enterprise Edition has a free software core with source-available additions. gitlab.com is a publicly hosted instance of GitLab Enterprise Edition (it offers features that are only available in GitLab EE). Luckily, GitLab’s barrier to entry is pretty low. The hardest part is registering an account. Forking and creating a merge request will (hopefully) be easy for anyone who’s already willing to create a patch. My biggest concern with GitLab is how centralized it is. Git is supposed to be a distributed version control system, but the design of GitHub, GitLab and other similar systems subverts Git’s distributed nature. As far as Git is concerned, commits can be fetched from pretty much anywhere. GitLab, on the other hand, requires that the instance that hosts the original repo also hosts the branch for the merge request. There’s certainly a lot of noise about changing that fact, but it doesn’t look like anything is implemented yet. This leaves me with two options: The first option is OK, but it’s certainly not ideal. The second option is definitely something that I don’t want to do. If I allow people to have accounts on a system that I control, then I would be responsible for: I don’t know how hard it would be to deal with any of those things or even if any of those things would be problems. The fact that I don’t know is the problem. I have zero experience hosting or running online communities, but I do know that it can be a very time consuming and thankless job. When I first started looking into Radicle, it looked promising. It’s free software. It’s very distributed (it’s pretty much a perfect 2!). Unfortunately, it has a two fatal flaws. The first is its barrier to entry. When I first tried Radicle, you pretty much had to have someone help you get started. I ended up figuring it out on my own, but it about 2 days of troubleshooting. The experience was frustrating. I’m sure that Radicle has improved since then, but I’m not sure by how much. The second flaw is more significant. At the moment, there’s no way for anyone to comment on patches. You could take a look at the email address in the patches’s commits, but there’s no guarantee that it will be a real address (in fact, when I started using Upstream, my email was set to I definitely like Radicle and want to use it for my projects, but it just isn’t quite ready yet. After looking into many of these solutions, I felt like I was missing something. If Git is supposed to be a distributed VCS, then shouldn’t there be a distributed way of submitting changes upstream? Did the Git developers just drop the ball here? As it turns out, the Git developers didn’t have to create a distributed system for submitting patches because one already existed. Historical context is important here. Git was created to help people develop the Linux kernel. Originally, Torvalds didn’t use version control at all. Contributors just sent their patches to a mailing list. When Linux started using version control, that fact didn’t change. Email can definitely be sent using only free software. Email is also fairly decentralized. The barrier to entry is about as low as it can get. Having an email address is (pretty much) a requirement for having a GitLab account. People are much more likely to already have email set up than they are to already have Radicle set up. Getting One potential problem with email is that it’s private by default. One very traditional solution to this problem is to use a mailing list. My concern with running a mailing list is very similar to my concern with running a GitLab instance. There’s a lot that can go wrong with email, and I have very little experience with running mail servers. The solution to that problem is public-inbox. It’s README says: I’ll still have to set up a new email address and worry about incoming mail. Public-inbox makes it so that I don’t have to worry about outgoing mail. As a bonus, public-inbox makes the system more distributed by using Git for the archive. Anyone can create a perfect mirror of a public-inbox by cloning its Git repo. Public-inbox is the way to go! I had come to that conclusion a while ago. The original plan was to set up public-inbox and then to write a blog post about it. Unfortunately, creating a well-oiled public-inbox isn’t exactly easy. The current plan is to write another post about some of the problems that I’m running into and then to start fixing them.The Three Qualities
You should be able to submit a patch using only free software
The barrier to entry should be low
[o]n an annual level, just over half of active projects (51%) have only 1 contributor, while 19% have 2, 9% have 3, 5% have 4, and 3% have 5 (see the PDF column below).
Having a low barrier to entry will (hopefully) increase the likelihood of someone actually contributing.The process should be distributed
The Candidates
GitHub
GitLab
[a]ll client-side JavaScript (when served directly or after being compiled, arranged, augmented, or combined), is licensed under the "MIT Expat" license.
This means that it’s definitely possible to submit a merge request to gitlab.com using only free software. Even if it wasn’t, I could always just host my own GitLab Community Edition instance.Radicle
<username>@<hash>). Even if the email address is correct, you would still only be able to comment on the patch privately. Public discourse is an important part of the bazaar development model, and Radicle doesn’t enable it yet.Email
git-send-email working can be challenging, but I can always have people run git-format-patch and send the results as an attachment.public-inbox stores mail in git repositories as documented
in https://public-inbox.org/public-inbox-v2-format.txt and
https://public-inbox.org/public-inbox-v1-format.txt
By storing (and optionally) exposing an inbox via git, it is
fast and efficient to host and mirror public-inboxes.
Traditional mailing lists use the "push" model. For readers,
that requires commitment to subscribe and effort to unsubscribe.
New readers may also have difficulty following existing
discussions if archives do not expose Message-ID and References
headers. List server admins are also burdened with delivery
failures.
public-inbox uses the "pull" model. Casual readers may
follow the list via NNTP, IMAP, Atom feed or HTML archives.
If a reader loses interest, they simply stop following.
Since we use git, mirrors are easy-to-setup, and lists are
easy-to-relocate to different mail addresses without losing
or splitting archives.
_Anybody_ may also setup a delivery-only mailing list server to
replay a public-inbox git archive to subscribers via SMTP.
Conclusion